分布式场景下的全局唯一ID生成
June 24, 2018
Written with StackEdit.
本文介绍分布式ID生成的几种思路
背景
底层数据存储时每条记录通常需要一个唯一ID来标识记录本身,然后根据该ID建立对应的各类索引列表。以微博为例,用户A发表的每条微博内容在底层存储时会为其分配一条索引ID,然后该ID也会写入follow的Timeline中(假设为写扩散模式)。各follower在阅读时先读取道好友发表的索引ID列表,然后根据其ID拉取微博内容。
分布式ID系统的目标
- 全局唯一
- 趋势有序
“有序”并非时必须的,实际使用中通常业务都会依赖ID的有序特性,来实现排序等特性。所以使用UUID之类简单粗暴的方案就不在我们讨论范围之内了。
思路
方案一:使用db的自增索引
这种在简单的架构设计中比较常见,如商品ID,入库时生成的uniqueid即为索引ID,生成方法以mysql为例:
mysql>CREATETABLE `get_max_id` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '业务主键',
`content` char(25) DEFAULT NULL COMMENT '业务内容',
PRIMARY KEY (`id`)
)ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
如何获取maxid之类的就不再详述。
除了mysql之外,也有一些类似的替代品,比如redis也提供了INCR指令。对使用方来说大同小异,做好组件的容灾即可。
优点
- 架构简单,小型业务足够使用
- 维护简单,只需要保证db的容灾
缺点
- 性能
- db单点
方案二:db扩展
方案1的方案还离分布式差得很远,在其基础上可以进一步扩展,比较常见的扩展方案有几种
多机器+不同的自增范围
使用不同的初始值和步长,可以解决生成id的冲突问题。当某一台db挂掉时,只会影响对应的seq序列。
批量获取
性能的瓶颈主要时因为过多的依赖db,为减少db的访问,可以一次从db获取多个ID,缓存到ID server的内存即可。实现方式上可以调整步长即可。
方案三:snowflake
snowflake是twitter用来生成唯一ID的服务,其产生的需求背景:
- 发表量大:每条上万条发表消息,高峰期峰值更加明显
- ID可排序:A和B同一时间发表的消息应该比较接近。这样客户端可以排序展示。
- 长度要求64bits以内
详见twitter的blog。
原理
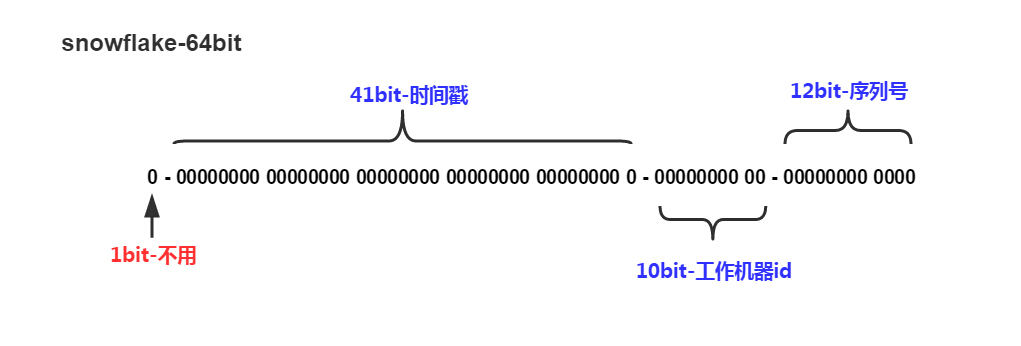
- 最高位是符号位,始终为0。
- 41位的时间序列(精确到毫秒,41位的长度可以使用69年)
- 10位的机器标识(10位的长度最多支持部署1024个节点)
- 12位的计数顺序号(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)
优点
- 高性能,低延迟;
- 可以根据自由的业务需求扩展变更
缺点
- 需要独立的开发和部署。
扩展
相对snowflake服务本身,其思想更值得借鉴。我们在使用时可以在其设计纸上进一步改造成符合业务的使用场景,比如在其中加入业务id、机房id等信息,这样也便于问题定位。
snowflake算法中的机器标识其实已经包含了路由信息。数据proxy层根据机器标志可以直接定位对应的worker ID,并将ID转发给对应的数据层处理读取请求。
底层在根据ID来读取数据时,根据底层存储模型的不同,这里可以有不同的实现。已bitcask模型为例:
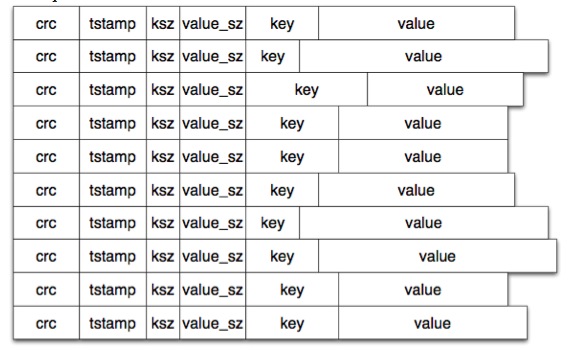
这里的ID(key)对存储层本身无任何关联,hash表中的value为数据存放的地址。对于存储层来说,只要上层保证ID唯一即可。
之前还见过另外一种存储模型,ID的产生跟底层数据存储强耦合,ID由数据存储层来生成,里面包含了机器、磁盘、存储偏移等信息。这种存储模型有几个好处:
- ID自带路由信息,不用再额外维护ID跟数据存储的映射。
- 不用再维护单独的ID service
- 逻辑层调用简单,一次调用即可完成写入
带来的缺点也很明显:
- 不支持update操作:数据ID不可变,其存储地址也不可变,这样导致存储的内容也可能变长等操作。如果需要update操作,只能以其他方式来绕过。
- 运维成本:因为ID跟存储地址有绑定关系,当机器故障需要替换时,需要确保备份机器的文件存储内容一模一样。否则通过偏移等定位数据时就会产生异常。
方案四:微信的序列号生成器
与上面各使用场景不同的是,微信的seq server主要用于client和server间数据同步,所以在实现目标上也有一定的差别:
- 只要求单用户空间内全局唯一,即用户A和用户B可能有相同的seqID
- 只要求单用户空间内趋势有序。

具体的实现方案参考这里。
其中对于“一组用户共享一个max_seq”的设计思路还是不错的。