可靠的分布式任务调度
October 10, 2021
Reliable Cron across the Planet...or How I stopped worrying and learned to love time
Štěpán Davidovič, Kavita Guliani, Google
前段时间预研分布式任务调度系统的方案,了解到了一个比较靠谱的解决方案:dkron,看介绍其实现就是基于基于google的这篇whitepaper 《Reliable Cron across the Planet》。
这篇文章也被收录到了书籍《SRE:google运维解密》一书中(第24章),于是将部分内容摘抄了一遍,补充了部分自己的理解,当做自己的读书笔记了。文章较长,部分个人认为不重要的内容就简单跳过了。
本文主要介绍了google的cron调度服务的实现机制,重点对实现的难点部分做了详细介绍。详见下文。
先对Cron系统的功能做了个简单的介绍。包括单机下crontab格式以及linux下的crond守护进程。此处略。
可靠性
从可靠性的角度来看待服务,需要注意几件事情。首先,故障域本质上只是一台机器,如果机器未运行,则Cron 调度程序及其启动的作业也不能运行(例如由于无法访问网络或尝试访问坏掉的硬盘驱动器导致的个别作业失败超出了本文分析的范围)。我们就先考虑使用两台机器的非常简单的分布式案例,其中 Cron 调度程序在单独的机器上运行作业(例如使用SSH)。我们就已经有了不同的可能会影响我们运行作业可靠性的故障域:调度程序或目标机器*可能会失败。
另一个重要方面是在 crond 重新启动(包括机器重新启动)时,需要持久化的唯一状态是 crontab配置 本身。Cron 执行者向来都是睡醒就忘的,而且 crond 也不会试图去跟踪它们的状态。
Cron任务和幂等性
Cron 工作常常被用于周期任务,但事实上我们很难预料它们可能执行的真正功能。让我们跑题一下,说说Cron 工作本身的行为,因为了解 Cron 工作的各种要求将成为文章其余部分中的一个主题,显然会影响我们的可靠性要求。
一些 Cron 作业是幂等的,并且在系统故障的情况下,可以安全地多次运行它们,例如垃圾收集,但是其他 Cron 任务则不然,例如,一个发送电子邮件的任务显然就不应该如此。
这种各种各样的 Cron 工作让我们难以定义故障模式:对于像 Cron 这样的服务,没有一个适合各种情况的单一答案。在本文中,我们倾向于采用跳过执行这种方法,而不是像其他基础架构那样采用有风险的再次运行。Cron 管理员可以(并且应该)监视他们的 Cron 任务,例如通过使 Cron 服务为其管理的任务显示状态,或者设置对 Cron 任务的影响的独立监控。如果跳过运行,Cron 管理员可以采取与任务性质相符的行动。相比之下,撤销再次运行可能就很困难了,在某些情况下(考虑发邮件的例子)甚至是不可能的。所以,我们更倾向于失效关闭(fail closed),避免系统自动地创建出不良状态。
大规模Cron系统
从单机迁移到大规模部署需要对如何使 Cron 在这样的环境中良好运行做一些根本性的反思,在介绍 Google Cron 解决方案的详细内容之前,让我们先讨论一下这些差异及其在设计上需要做的改变。
基础设施扩展
普通 Cron 限于单机,然而,对于大规模的系统部署,我们的 Cron 解决方案却不能与单机绑定。假设如果我们一个单独的数据中心有 1000 台机器,那么只要有 1/1000 的机器发生故障都将会引起整个 Cron 服务不可用,显而易见,这肯定是不可接受的。
为了解决这个常见的问题,我们将任务进程与物理机器解耦。如果你想要运行某个服务,只需指定在哪个数据中心运行以及要运行的服务,然后数据中心内的任务调度系统(data center scheduling system,本身应该是可靠的)就可以接管并决定要哪些机器去运行它。“在数据中心中运行一个任务”就有效的转换为“发送一个或多个RPC请求到数据中心的调度程序”。
说明:google的实现中,Cron Service不负责具体的任务执行,只负责发起任务和接收结果。具体任务执行通过RPC调用,转给数据中心内的任务调度(分发)系统来安排,任务调度系统根据任务所需的资源分配具体执行的机器、 容器节点。google的基建已经很完善了,所以本文的重点也仅限于描述Cron Service的实现。业界部分分布式调度系统实现将整个系统拆分为调度(schedular)和执行(executor)两个独立模块,调度只负责管理任务和状态存储,但是具体的调度交给executor去完成。
但是,任务进程执行是需要时间的,有可能发生在 发现机器宕机(健康检查超时)和 将作业重新调度到不同机器(软件安装,过程启动时间)之间。
由于将任务进程移动到不同的机器,那就可能意味着可能存在丢失存储在旧机器上的任何本地状态(除非采用实时迁移),并且重新调度时延可能会超过cron最小时间间隔一分钟,所以我们应该清楚如何应对这个情况。最明显的选择之一是简单地将状态保存在分布式文件系统(如GFS)上,并在启动期间使用它来识别由于重新安排而无法启动的作业,这种方案可以让作业快速失败,但是,如果是每五分钟运行一次 Cron 作业,那么由于重新调度导致的延迟时间是一分钟或两分钟,那么这个时间间隔其实就长调度周期的很大一部分了。
对需求的扩展
将Cron系统部署到整个数据中心级别,一般来说意味着将进程部署到容器中,以便更好地进行资源隔离。在这里,隔离是很有必要的,因为数据中心中每个独立进程不会互相影响是一个基础性假设。为了保证这种假设有效,我们必须在每个进程运行之前知道它预计使用的资源—不管是Cron系统本身,还是该系统所要运行的任务。某个Cron任务可能由于数据中心没有足够资源满足该任务而延迟。这种资源要求,加上用户对任务运行情况的监控需要,使得我们需要记录Cron任务的全过程,从预计执行一直到任务终止。
将进程启动过程与具体运行的机器分离使得整个Cron系统需要处理“部分失败”(partial launch failures)的故障类型。Cron任务的多样性意味着某些任务在启动的时候可能需要发送多个RPC,有时我们会遇到某个RPC成功,而其他RPC不成功的问题(例如,发送RPC的进程本身在发送过程中崩溃了)。Cron 故障恢复过程必须要处理这种情况。
在讨论故障模式的时候,一个数据中心相比单个物理机来说是一个更加丰富的生态系统。Cron服务,当大规模部署时从一个简单的二进制文件演变成了一个具有许多明显和不明显的依赖的服务。对Cron这样的基础服务来说,必须保证在数据中心遇到部分故障的时候(例如部分供电系统故障,或者存储系统故障),整个服务仍然能够正常运行。通过在数据中心内部分散地同时运行多份调度器的副本,我们可以避免单个供电单元故障造成整个Cron系统不可用。
将Cron服务部署在全球范围内可能是可行的,但是将Cron部署在一个单独的数据中心中有其对应的好处:该服务与其对应的数据中心任务分发系统延迟很低,同时共享一个故障域。毕竟,数据中心任务分发系统是Cron服务的一个核心依赖。
google Cron系统的构建过程
本节主要展示构建一个可靠的大型分布式Cron系统所必须要解决的问题。同时也强调了Google的分布式Cron服务的几个设计要点。
跟踪Cron任务的状态
如上一节所述,我们需要记录关于Cron任务的一些状态信息,并且必须能够在系统发生故障的时候快速恢复。更重要的是,该状态信息的一致性是关键!还记得前文所述的那些发送邮件和计算工资之类的非幂等的Cron任务吗?
跟踪任务的状态有两个选项:
● 将数据存储在一个可用度很高的外部分布式存储上。
● 系统内部自行存储一些(很小量的)状态信息。
当Google设计分布式Cron任务的时候,我们选择的是第二个选项。这样选择的原因有以下几个:
● 分布式文件系统,包括GFS和HDFS通常用来存储非常大的文件(例如,网页爬虫程序的输出文件),而我们需要存储的Cron任务状态信息通常来说是非常小的。小型写操作在分布式文件系统上的开销很高,同时延迟也很高,因为这些文件系统就不是为这种类型的写操作进行优化的。
● 基础服务,也就是那些失效时会带来许多副作用的(就像Cron这样的)服务应该依赖越少越好。即使数据中心的一部分出现故障,Cron服务也应该能够持续工作一段时间。但是这个要求并不一定意味着存储区域一定要在Cron进程内部(存储部分其实只是一个实现细节)。然而,Cron服务应该可以独立于下游系统而运行,以便服务更多的内部用户。
说明:之前了解的一些外部开源实现方案中,部分采用了mysql、redis之类的外部依赖来存储状态数据,好处是实现简单,不用考虑数据一致性问题。坏处在于加入了第三方的依赖,而且也没有解决唯一主调度的问题,需要额外引入etcd等组件来完成竞争锁等机制。google的实现引入了Paxos组件来解决选举及数据同步的问题。
Paxos协议的使用
我们为Cron服务部署了多个副本,同时采用Paxos分布式共识算法保证它们状态的一致。就算某些基础设施出现故障,只要整个组中大多数成员可用,整个分布式系统就可以顺利地进行状态变更。
分布式 Cron 使用单个主副本,如图所示,它是唯一可以修改共享状态的副本,也可以是启动 Cron 作业的唯一副本。我们利用 Paxos 的变体(称为 Fast Paxos)在内部使用主副本作为优化 - Fast Paxos 主副本也充当Cron服务主机。
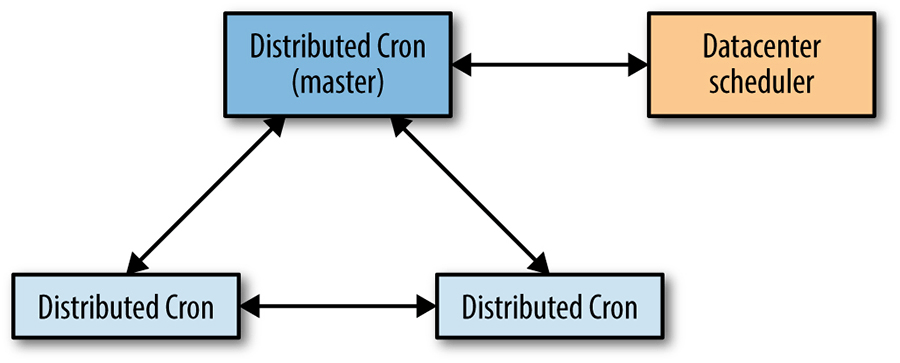
如果主副本崩溃了,Paxos 组的健康检查会很快发现这个问题(通常在几秒之内)。由于已经有另外几个Cron进程处于启动状态,所以可以很快地选举出一个新的主副本。一旦新的主副本选举出来,根据Cron服务自定义的选举过程使得新的主副本进程接手之前领头人未完成的工作。虽然Cron服务的主副本进程和Paxos协议的主副本进程其实是一个,但是Cron主副本在选举结束后需要完成一系列额外的操作。选举速度很快,使我们可以很轻松地保证在可接受的一分钟故障时间内进行故障切换。
各个副本利用Paxos协议同步的最重要的状态信息就是哪些Cron任务已经被启动了。该服务需要不停地以同步方式通知大多数的副本每个计划任务的启动和结束信息。因为每个任务的调度周期计算时需要了解上次的执行起止时间。
主从副本角色
正如前文所述,Cron服务使用Paxos协议分配两个角色:领导者(主副本、the master)和追随者(从副本、the slave)。下文会详述每种角色的职责。
The Master
主副本进程是唯一一个主动启动Cron任务的进程。该进程内部有一个内置调度器,与本章开头提到的简单的crond实现非常类似。该调度器按照预定的启动时间排序维护一个Cron任务列表。进程在第一个任务的预期执行时间之前一直处于等待状态。当到达预定启动时间时,主副本宣布它将要开始启动该Cron任务,同时计算新的(下一次的)启动时间,和普通的crond实现一样。当然,与普通的crond类似,自从上次执行过后,Cron任务的启动条件可能已经变化了,这些启动信息也必须同步给其他所有的副本角色。简单地标记某个Cron任务是不够的,应该将某次启动时间作为唯一标识符标记;否则在记录Cron任务的启动时可能会产生歧义(这种歧义通常出现在那些高频任务中,比如那些每分钟运行一次的任务)。如所示,全部通信都是基于Paxos协议之上完成的
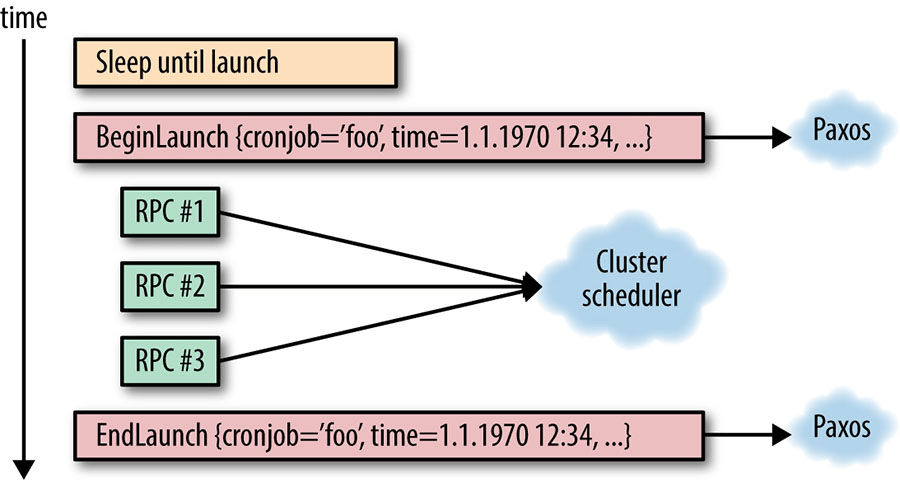
Paxos 通信的同步性是很重要的,Cron任务的实际启动在得到Paxos法定仲裁过程结束之前不会进行。Cron服务需要知道每个任务是否已经启动了,这样才能在主副本切换的时候决定正确的操作。如果这些操作是异步进行的,可能意味着整个任务的启动过程都在主副本进程上已完成,而没有通知到其他的副本。当故障切换的时候,新的主副本可能会重新进行这次启动,因为它们不知道这个任务已经被启动过一次了。
Cron任务启动过程的完成也需要通过Paxos协议同步通知给其他的副本。要注意的是,我们这里仅仅记录了Cron服务在某个时间试图进行一次启动操作,并不关心这次启动是否真正成功或者是否由于外部原因失败了(例如,如果数据中心任务分发系统当前不可用)。下文会提到如何处理发生在这项操作过程中的问题。
另外一个作为主副本角色非常重要的功能是,当其由于各种原因失去主副本角色时,该进程必须立刻终止一切和数据中心任务分发系统之间的交互。主副本角色必须意味着对数据中心级别任务分发服务的独占性。如果缺少了这种独占性,新旧主副本进程同时进行相互冲突的操作。
The Slave
从副本需要持续跟踪主副本进程提供的目前的系统状态,以便在需要的时候及时替换。所有的状态改变都是从主副本角色基于Paxos协议传递的。就像主副本角色那样,从副本也必须要维护系统中所有Cron任务的列表,这个列表必须在所有副本中保持一致(这就是要使用Paxos协议的原因)。
当接收到某个已经执行的“启动”通知时,从副本需要更新该副本内部该任务的下次预计启动时间。这项重要的状态改变(是同步进行的)保证了所有Cron任务在整个系统中的状态是一致的。我们同时也会记录所有的未完成启动。
如果主副本进程崩溃,或者由于其他某个原因不再正常工作(例如,由于网络分区问题无法联系到其他的副本),某个从副本进程将会被选举为新的主副本进程。该选举过程必须要在一分钟之内完成,这样可以避免大幅延迟或者跳过某个任务的执行。一旦一个新的主副本被选举出来,所有的未完成状态的启动过程必须被结束。这个过程可能是很复杂的,通常需要Cron系统和数据中心基础服务的共同协作才能完成。下面这一小节会详细讨论如何解决这种部分性失败情况。
解决部分性失败问题
正如上文所述,主副本进程和数据中心调度系统之间的单个任务启动的过程可能在多个RPC中间失败。我们的系统应该能处理这种状况。
前文说过,每个任务启动都具有两个Paxos同步点:
● 当任务启动执行之前
● 当任务启动执行之后
这两个同步点使我们可以界定每一次具体的启动。就算启动过程仅仅需要一个RPC,我们怎么能够知道这个RPC是否已经发出了呢?这里还包括在标记启动已经执行之后,但是启动结束通知发送之前主副本进程就崩溃了的情况。
为解决部分失败的问题,有两种思路可选:
● 所有需要在选举过后继续的任务,对外部系统的操作必须是幂等的(这样我们可以在选举过后重新进行该操作)。
● 必须能够通过查询外部系统状态来无疑义地决定某次操作是否已经成功。
这两个选项中的任意一个都是很大的挑战,可能很难实现。但是实现其中的至少一个是在大型分布式系统中应对单点或多点故障并准确运行一个Cron系统的前提。如果没有正确地处理这些情况,可能会导致错过某些任务的执行,或者重复运行某些任务。
在数据中心中管理逻辑性任务的大部分基础设施(例如Mesos)会为这些任务提供某种命名服务,使我们可以通过这些名字查找任务状态、停止任务,或者进行其他的维护操作。一种解决幂等性问题的方案是提前构建一致的任务名称,并且分发给所有的Cron服务副本(这样就可避免在数据中心调度器上进行任何的修改操作)。如果主副本在启动过程中崩溃,新的主副本可以通过预计算的任务名称来查询任务的状态。
上文说过,我们在副本之间同步信息的时候会记录预期启动时间。同样的,我们需要将Cron服务与数据中心调度器的交互也使用预期启动时间唯一标识。例如,假设有一个高频运行的,但是运行时间很短的任务。该任务成功启动,但是在启动成功的信息同步到其他副本之前,主副本进程崩溃了。同时故障切换机制由于某种问题造成了延迟,迟到足够这个任务已经结束了。新的主副本进程查询该任务的状态,发现该任务目前处于完成状态,于是尝试再次启动该任务。如果预期启动时间被包含在任务名中,新的领头人副本就可以准确地知道这个任务其实是任务的某个特定启动,于是就避免了这种双重启动情况的发生。
在实际的实现中,状态的查询由一个比较复杂的系统组成,这主要是由于底层基础设施的实现细节所决定的。然而,前面的描述适用于任何系统。取决于具体的基础设施,实现者可能要在双重启动的风险和错过启动的风险中进行抉择。
说明:失败问题应该是整个系统最复杂的部分,仅依靠Cron Service自身是无法解决的,需要借助数据中心调度系统等外部能力。其中一种幂等性问题的解决方案是给每次调度唯一的id。任务执行中或结束后更新相关任务状态到外部系统,容灾切换后新的主副本在执行前先查询上次的执行结果,避免重复执行。
状态存储
使用Paxos 协议来达成共识只是状态问题的一部分。Paxos 基本上是一个只能新增的日志,在每次状态变化后同步地新增。Paxos协议的这种特性意味着以下两个问题:日志需要定期压缩,以防无限增长;日志必须要存储在某个地方。
为了避免Paxos日志的无限增长,可以简单地将目前的状态进行一次快照(snapshot)。这就意味着我们可以不再需要重新回放之前的所有状态改变来得到目前的状态。提供一个例子:如果我们的状态变化存储在日志中的时候是“将某个计数器加1”,那么在1000次迭代之后,可以用一个“将计数器设置为1000”来替代1000条记录。
在日志丢失的情况下,我们只会丢失上次快照之后的信息。快照也是我们最重要的状态信息—如果丢失快照信息,我们就必须从零开始,因为已经丢失了全部内部状态。相比之下,丢失日志仅仅会将Cron系统重置回上次快照的时间。
存储数据有两个方案:● 外部可用的分布式存储。● 在系统内部存储少量的数据。当设计该系统时,我们采取了一个综合两个选项的方案。
我们将Paxos日志存储在服务副本运行的本地磁盘上。在标准情况下,我们有三个副本运行,也就是有三份日志。同时我们也将快照信息保存在本地磁盘上,然而因为这些信息很重要,会同时将它们备份到一个分布式存储上去。这样可以为三个机器同时出现问题的情况提供保护。
我们并不将日志直接存储在分布式文件系统上。我们认为丢失日志,也就是丢失一小部分最近的状态改变是一个可以接受的危险。将日志保存在分布式文件系统上可能会造成很严重的性能问题—由大量的小型写操作引起。三个机器同时出现故障是很罕见的,而且如果的确同时发生故障了,我们会自动从快照中恢复。于是,我们仅仅只会丢失一小部分日志信息:这些都是自从上次快照之后产生的。而快照是根据预先配置的时间间隔自动产生的。当然,这些妥协可能根据基础设施的细节而不同,也与Cron系统本身的要求有关系。
除了在本地存储的日志和快照,以及分布式文件系统上的快照备份之外,一个刚刚启动的副本可以从另外一个已经运行的副本上获得最新的快照和日志。这个能力使得启动过程可以独立于本地物理机器的任何状态。因此,将系统的某个副本重启,重新调度到另外一台物理机器上(或者由于物理机器故障原因迁移)对服务稳定性来说没有影响。
Running a Large Cron
运维一个大型Cron系统同样有一些较小但是也很有趣的问题。传统的Cron系统规模通常很小,最多可能由几十个任务组成。但是,如果我们在一个数千台机器的数据中心上运行Cron系统,系统的用量可能会大幅增加,同时可能会造成一定的问题。
一定要小心任何大型分布式系统都熟知的问题:惊群效应(thundering herd)。根据用户的配置,Cron服务可能会造成数据中心的峰值效应。当人们想要配置一个“每日任务”时,他们通常会配置该任务在午夜时运行。这个配置可能在一台机器上还可行,但是当你的任务会产生数千个MapReduce工作进程的时候就不可行了。尤其是当其他30个团队也按照同样的配置在同一个数据中心来运行每日任务呢?为了解决这个问题,我们在crontab 格式上增加了一些扩展。
在普通crontab格式中,用户用分钟、小时、月中的日期(或者周内的日期),以及月份来标记某个任务应该运行的时间,或者使用“*”来标记任意值。每天在午夜时候运行会将crontab标记为“0 0 * * *”(也就是0分0时,月内的每一天,每个月,以及周内的每一天都会运行)。我们在这里增加了一个问号“?”,意味着任意一个值都可以接受,Cron系统可以根据需要自行选择一个时间。用户可以将任务分散在整个事件序列里(例如[插图]中的某个小时),因此可以将这些任务分散得更为均匀。
就算引入了这个改动,Cron任务带来的系统负载仍然是非常尖锐的。如图所示的是,聚合过的Google全球Cron任务启动数量图。这个图片集中展示了Cron任务经常性的负载峰值,这是因为某些任务需要在特定时间启动—例如,由于对外部事件的某些临时依赖造成。

说明:典型的峰值问题,根据实际情况想办法削峰即可。cron确实会存在这类问题。
Summary
A Cron service has been a fundamental feature in UNIX systems for decades. The industry move toward large distributed systems, where a data center may be the smallest unit of hardware, requires changes in large portions of the stack, and Cron is no exception. A careful look at the required properties of a Cron service and the requirements of Cron jobs drives our new design.
We have discussed the new constraints and a possible design of a Cron service in a distributed system environment, based on the Google solution. The solution requires strong consistency guarantees in the distributed environment. The core of the distributed Cron implementation is therefore Paxos, a common algorithm for reaching consensus in an unreliable environment. The use of Paxos and correct analysis of new failure modes of Cron jobs in a large-scale, distributed environment allowed us to build a robust Cron service that is heavily used at Google.
Acknowledgments
Many thanks to Dermot Duffy and Gabriel Krabbe (designers of the foundation of the system described in this article), Derek Jackson, Chris Jones, Laura Nolan, Niall Murphy, and all other contributors and reviewers for their valuable input on this article.
References
- Burrows, M. 2006. The Chubby lock service for loosely-coupled distributed systems. Proceedings of the 7th Symposium on Operating Systems Design and Implementation: 335-350. http://research.google.com/archive/chubby-osdi06.pdf
- Corbett, J. C., et al. 2012. Spanner: Google's globally-distributed database, Proceedings of OSDI'12. Tenth Symposium on Operating System Design and Implementation. http://research.google.com/archive/spanner-osdi2012.pdf
- Docker. https://www.docker.com/
- Junqueira, F. P., Reed, B. C., Serafini, M. 2011. Zab: High-performance broadcast for primary-backup systems. Dependable Systems & Networks (DSN), 2011 IEEE/IFIP 41st International Conference: 245-256. http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=5958223&tag=1
- Lamport, L. 2001. Paxos made simple. ACM SIGACT News 32 (4): 18-25, http://research.microsoft.com/en-us/um/people/lamport/pubs/pubs.html#paxos-simple
- Lamport, L. 2006. Fast Paxos. Distributed Computing 19 (2): 79-103, http://research.microsoft.com/pubs/64624/tr-2005-112.pdf
- Ongaro, D., Ousterhout, J. 2014. In search of an understandable consensus algorithm (extended version). https://ramcloud.stanford.edu/raft.pdf